How AI Engines Actually Decide What to Cite
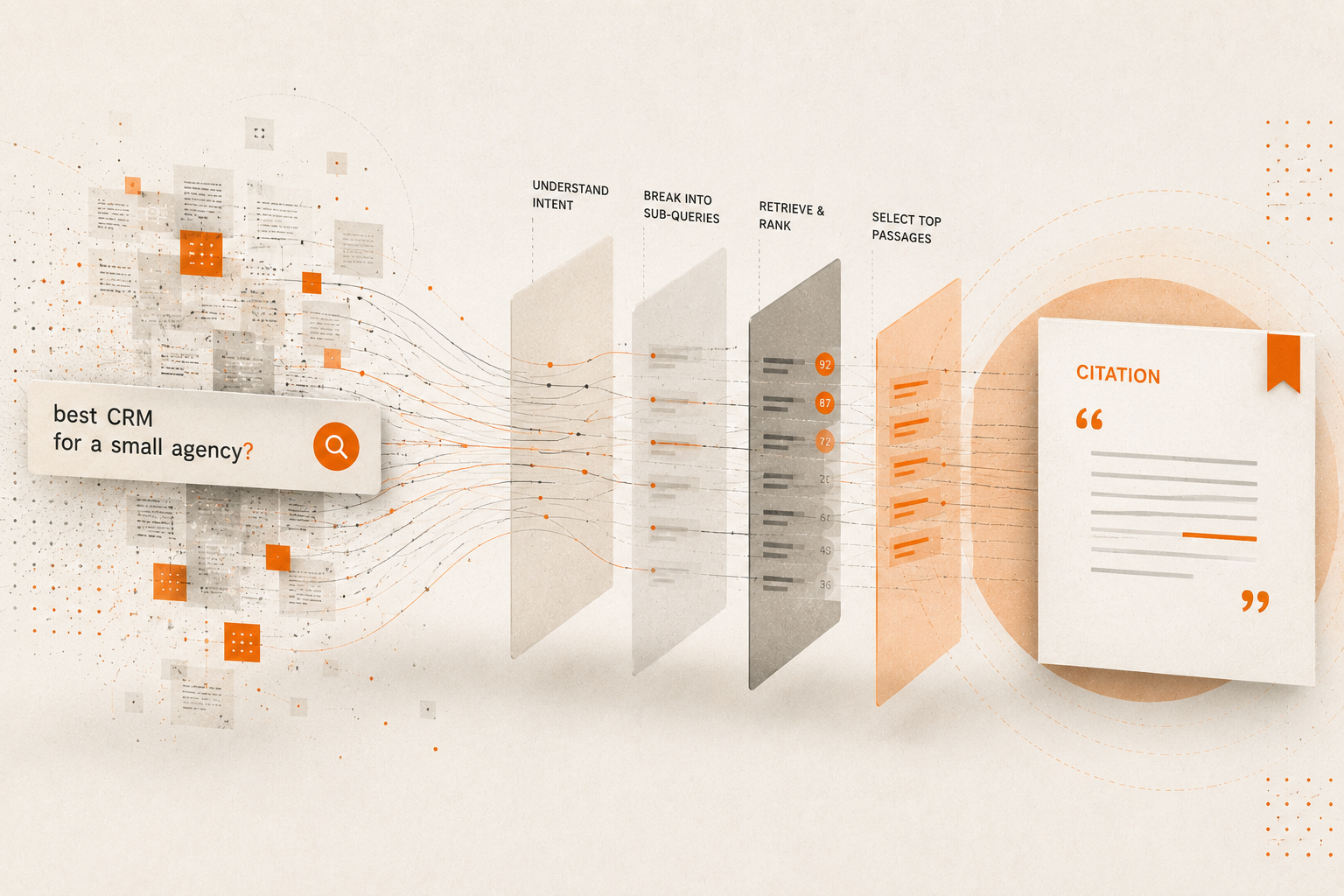
Retrieval-Augmented Generation is the mechanism behind every AI citation. The engine breaks your prompt into narrower sub-queries, retrieves a candidate set of passages, scores each by relevance and authority, then synthesizes the answer and attributes the pieces it used. Teams that understand RAG mechanics optimize systematically. Everyone else optimizes by guessing.
Most people picture an AI engine reading their page the way a person would, top to bottom, weighing the argument. That is not what happens. The engine never sees your page as a page. It sees a pool of text fragments, ranked by math, and it pulls the few that answer the specific question in front of it. If you know how that pool gets built and ranked, you can write for it. If you do not, you are publishing into a process you cannot see.
What is RAG and how does it work?
Retrieval-Augmented Generation is a technique that lets a language model pull in external text before it answers, instead of relying only on what it learned during training. The model first retrieves relevant documents from an index or a live web search, then generates its response grounded in that retrieved material. This is the structure behind grounded answers in ChatGPT, Perplexity, Google’s AI surfaces, and Claude when web access is on.
The reason RAG exists is accuracy. A model working from training data alone has a fixed knowledge cutoff and a tendency to fabricate specifics. By blending generation with a retrieval step, the engine sticks closer to source material and can show its work. That last part matters for you! A system that retrieves before it answers is a system that has to choose sources, and any choice can be reverse-engineered.
There are two retrieval modes worth separating.
Real-time RAG fetches live web pages during the query, which is how Perplexity and ChatGPT’s search mode operate. Training-data answers come from pre-learned knowledge with no live fetch. The architecture decides the behavior. A page can sit at position one in Google and still never get cited, because the engine runs a separate evaluation for whether your text is extractable and trustworthy enough to fold into a written answer.
What happens between your prompt and the citation?
The whole thing runs in the time it takes the answer to start streaming, which is why it feels instant. Underneath, several steps fire in sequence. The engine analyzes intent, decomposes the prompt into sub-queries, runs those searches in parallel, assembles a candidate set of passages, scores them, and synthesizes a response that attributes the fragments it actually used.
The synthesis step is where citation happens. The model is not citing your domain because it respects your brand. It is citing the specific passage it lifted to satisfy one sub-query. Your page can contribute one sentence to an answer that pulls from five other sources, and that single contribution is your citation. This reframes the entire optimization target. You are not trying to win a page. You are trying to own a passage that answers a question cleanly enough to survive the scoring step.
Why does prompt decomposition matter for AEO?
Prompt decomposition, often called query fan-out, is the step where the engine breaks one complex prompt into several narrower sub-queries and searches each independently. A prompt like “best CRM for a small agency” does not run as one search. It fans out into questions about pricing, integrations, ease of use, small-team features, and real user reviews, even though the user typed none of those explicitly.
A single prompt can spawn anywhere from a handful to twenty or more sub-queries depending on complexity. Each one runs its own retrieval. This is the mechanic that breaks keyword-era thinking. You might rank beautifully for the headline phrase and stay invisible to the sub-queries that actually decide the citations, because a competitor answered those adjacent questions better than you did.
The practical move is to map the fan-out before you write.
List the questions a thorough answer would need to resolve, then make sure your content resolves each one in a discrete, self-contained section. Semrush ran a controlled test optimizing four articles specifically against fan-out queries and saw citations of those pieces more than double. The lesson is that owning the supporting questions, not just the headline term, is what gets you pulled into answers.
How does the engine score candidate sources?
Once the candidate passages are assembled, the engine ranks them on two axes that pull in different directions: relevance and authority.
Relevance is semantic match, measured by how close your passage sits to the sub-query in vector space, the mathematical representation of meaning. Authority is the trust layer, the signals that say this source is reliable enough to repeat.
Relevance usually does the heavy lifting. Research on ChatGPT citations across millions of prompts found that within a given retrieval set, freshness and authority matter, but relevance to the fanned-out queries is what determines whether a retrieved page actually gets cited rather than just fetched and ignored. A new page that matches the sub-queries well gets cited. A new page that does not gets retrieved and dropped.
Authority becomes the tie-breaker when relevance is close. In news queries, where many pages match the topic almost identically, engines fall back on page age and source reputation to break the tie. Academic work points the same direction: studies of ChatGPT’s source selection in scholarly contexts found it leans heavily on citation-count signals and well-known journals, amplifying sources that already carry consensus weight. The takeaway for your content is that relevance gets you into the candidate set, and authority decides close calls. You need both, in that order.
Why does answer block placement on your page change citation odds?
The engine retrieves passages, not pages, and it extracts the chunk that most cleanly answers the sub-query. If your answer is buried in the eighth paragraph behind setup and throat-clearing, the extractable unit is harder to isolate and easier to skip in favor of a competitor who stated the answer directly. Structure is not decoration here. It is what makes a passage machine-parsable.
This is the entire case for answer-first writing. Lead a section with a direct, declarative statement that contains the exact phrasing of the question, then support it underneath. A section that opens with its own answer is a clean extraction target. A section that winds up to its answer forces the engine to do work it will often skip. The H2s on your page function like an index of questions; each one should be answerable from the first lines beneath it without the engine needing the rest of the section.
What signals does each engine weight differently?
The engines do not behave alike, and treating them as one target wastes effort. Perplexity cites generously, averaging around 6.6 sources per response, and holds onto those citations longer. ChatGPT cites far fewer, typically three to four domains per response, and churns through them fast. Google’s AI surfaces cite the most, often more than a dozen domains, with a more stable core set per prompt.
Source turnover is the sharpest difference.
SISTRIX tracked source stability across 82,619 prompts over 17 weeks and found ChatGPT replaces roughly 74% of its cited domains every week, while Google replaces around 56%. The median ChatGPT prompt does not hold a single domain across all 17 weeks. Google’s AI Mode, by contrast, tends to keep a stable core of a couple of domains per prompt plus a rotating carousel.
There is also a freshness split. Analysis of millions of citations found ChatGPT skews toward fresher content than Google’s organic results by a wide margin, yet the median age of pages it cites still lands around 500 days, with some cited pages over seven years old. Freshness is a strong signal, especially for news, but it does not override relevance. The strategic read is that platform choice changes your tactics more than your industry does. A piece optimized for Perplexity’s durable, multi-source behavior is a different artifact from one chasing ChatGPT’s fast-rotating, few-source answers.
How can you reverse-engineer which prompts your content can win?
Start from the fan-out, not the keyword. Take a prompt your audience actually types and decompose it yourself into the sub-queries an engine would generate. Free fan-out simulators exist for this, and so does manual work: write down every question a complete answer would have to resolve. That list is your real target set.
Then check which of those sub-queries you already answer cleanly and which you do not. Run the prompt through the engines you care about and read which domains get cited for each facet. The sources winning the sub-queries you are missing are your direct competition for that answer, and the gap between their passages and yours is your edit list. This is more honest than a rank check, because it tells you which specific questions your content can credibly win rather than which phrases you happen to rank for.
What can you change this week based on RAG mechanics?
Three moves, none of which require a rebuild. First, convert your H2s into the actual questions your audience asks, and make the first two sentences under each one a complete, standalone answer. That single change turns vague sections into clean extraction targets.
Second, map the fan-out for your two or three highest-value pages and add sections for the sub-queries you are not yet answering. You are filling the gaps that decide citations, not adding filler. Third, pick your platform priority deliberately. If your audience lives in Perplexity, lean into depth and durable, well-sourced passages that survive its longer citation window. If they live in ChatGPT, accept the fast churn and build a publishing cadence that re-earns citations rather than expecting one piece to hold. The mechanics are knowable. The teams that act on them stop guessing.
FAQ
Is RAG the same as web search inside AI?
Not exactly. Web search is one source RAG can retrieve from, but RAG is the broader pattern of fetching external text and grounding the answer in it. That text can come from a live web crawl, a private document store, or a vector index. When ChatGPT or Perplexity searches the web mid-answer, that is RAG using web search as its retrieval layer. RAG over a company’s internal docs uses no web search at all.
Why do AI engines cite different sources for the same prompt?
Because each engine decomposes the prompt differently, retrieves from different indexes, and weights relevance, authority, and freshness on its own curve. ChatGPT pulls three to four fast-rotating domains, Perplexity pulls around 6.6 and holds them longer, and Google’s AI Mode pulls a dozen or more with a stable core. Same question, different fan-out, different scoring, different citations. Source rotation compounds it: ChatGPT alone swaps roughly 74% of its cited domains week to week.
Does the citation half-life data still apply?
Yes, and it is more useful than a single fabricated number. Research on 3.5 million citation events puts ChatGPT’s citation half-life at about 3.4 weeks, the fastest of the major platforms, with Perplexity nearly 70% longer at 5.8 weeks and Google’s surfaces clustered in the four-to-five-week range. The practical meaning is that a ChatGPT citation needs re-earning roughly monthly, while a Perplexity citation works for you longer. Plan your publishing cadence around the platform you are optimizing for.