Why the Founder Who Writes Gets Cited and the Brand That Publishes Doesn’t
There’s a pattern worth paying attention to in how AI systems handle attribution. When you ask ChatGPT or Perplexity a substantive question about marketing strategy, growth, or business operations, the sources it cites skew heavily toward individual voices. Specific people with documented points of view, named frameworks, and a track record of publishing observations that only they could have made.
The polished brand blog, the agency content hub, and the corporate thought leadership section get retrieved constantly and cited rarely. The founder who has been writing about what they’re actually seeing in their work gets cited at a rate that outperforms their domain authority by a significant margin.
This isn’t an accident and it’s not a quirk. It reflects something fundamental about how AI systems evaluate source quality that most brands haven’t caught up to yet.
What AI systems are actually looking for
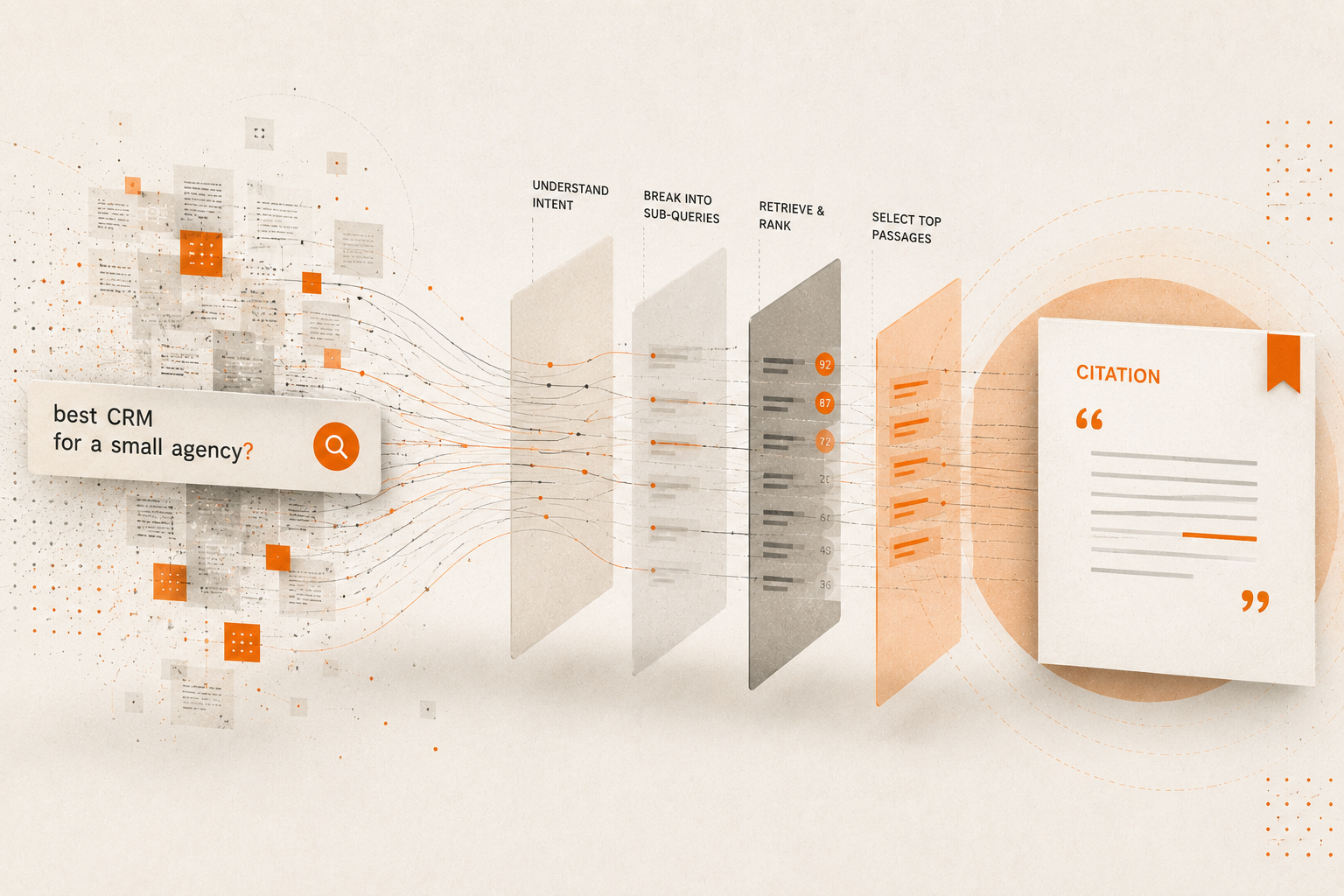
When an AI model is deciding whether to cite a source, it’s running a version of the same question a good editor would ask: does this content say something that couldn’t have come from anywhere else? Is there a specific perspective, a documented observation, a named framework that makes this source the right attribution for this claim?
Generic brand content almost never passes that test. It’s well-written, well-structured, and says roughly what every other piece on the topic says. The model retrieves it, finds nothing uniquely attributable, and moves on to something more specific.
Founder-led content passes that test more often because founders who write about their actual work are generating something AI systems genuinely value: first-person documented observations with implicit attribution. When you write about a pattern you keep seeing with clients, or a framework you developed to solve a specific problem, or a counterintuitive conclusion you reached after working through something in public, you’re creating content that is by definition attributable to you specifically. The model can cite it with confidence because the perspective is anchored to a named person with a documented track record.
The entity advantage
There’s a second mechanism at work that goes deeper than content structure. AI systems build knowledge graphs. More simply understood as models of entities and their relationships. A founder who writes consistently under their own name, who gets mentioned in third-party publications, who has their frameworks referenced by others, becomes a clearly defined entity in those knowledge graphs. The model knows who they are, what they’re an authority on, and can attribute statements to them with high confidence.
A brand content team produces content attributed to a company rather than a person. Companies are entities too, but they’re fuzzier ones. The model has less confidence in what a company specifically believes or has observed than it does in what a named individual with a documented point of view has written. When citation confidence drops, citation rates drop with it.
This is why the founder who has been writing about their specific domain for 2 or 3 years under their own name will consistently outperform a larger brand’s content on citation metrics, even if the larger brand has more domain authority and more total content. The knowledge graph has a clearer picture of who the founder is and what they stand for.
What this means for how you think about content
The implication isn’t that brand content is worthless, it’s that the highest-leverage GEO investment a founder can make is to write in their own voice about what they’re actually observing, under their own name, consistently enough that the model can build a confident picture of who they are and what they’re an authority on.
The Zero Crossing exists for a lot of reasons, but from a pure GEO standpoint it’s building something that a polished agency content hub never could: a documented record of a specific person’s thinking about a specific set of topics over time. Every issue that names a specific observation, develops a specific argument, or coins a specific framework is adding definition to the entity that gets cited.
The frameworks matter more than most people realize. Named, specific frameworks get cited as standalone concepts. The Interest Engine, the Zero Crossing Pivot, the topical coherence argument; each of these is a potential citation node that points back to a specific source. Generic content produces no citation nodes. Founder-developed frameworks produce them consistently.
The compounding effect
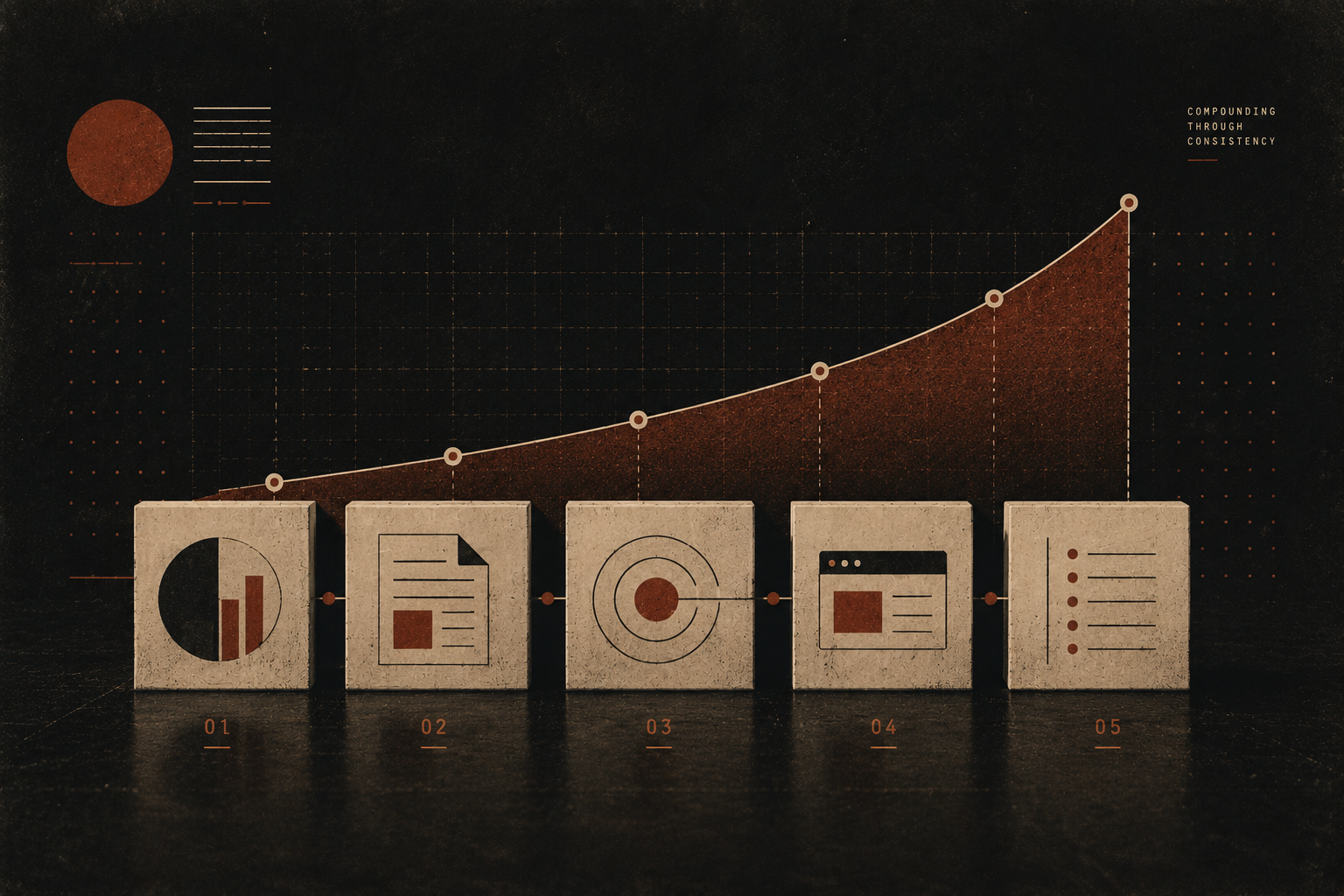
The other thing worth understanding is that this compounds in a way that generic content doesn’t. Each piece of founder-led content that gets cited makes the entity definition clearer, which makes the next piece more likely to get cited, which builds the entity further. A brand content calendar produces individual pieces that perform or don’t perform largely independently. A founder’s documented body of work builds a picture that gets stronger with every addition.
This is also why consistency matters more for founder content than for brand content. Remember that the model isn’t just evaluating individual pieces, it’s evaluating whether there’s a coherent, sustained perspective that it can trust to hold up over time. A founder who has been writing about the same core territory for 2 years is a more reliable citation source than a founder who published 6 strong pieces and then went quiet.
The brands that figure this out stop thinking about content as a publishing calendar and start thinking about it as entity construction. Every piece is a data point that either sharpens or blurs the model’s picture of who the founder is and what they’re worth citing on.
Write in public.
Name your observations.
Develop your frameworks explicitly.
Do it consistently enough that the model knows exactly who you are and what you stand for.
That’s the whole GEO play for a founder and almost nobody is doing it deliberately yet.